

Project Overview
This project investigates urban sound classification through two main tracks:
- Deep Learning: Employing advanced neural networks to analyze image-based features (melspectrograms).
- Machine Learning: Leveraging traditional algorithms to classify tabular datasets based on audio features.
Both tracks include feature extraction, exploratory data analysis (EDA), model training, and performance evaluation. Additionally, A/B testing was conducted to assess the success of a newly introduced sound class, Love, and the impact of various scaling techniques on machine learning models.
About the Dataset
The UrbanSound8K dataset is a popular benchmark for urban sound classification, containing 8,732 labeled audio files (<= 4 seconds) across 10 classes, such as car horns, dog barking, and engine idling.
In this project:
- Deep Learning leverages melspectrogram images as features.
- Machine Learning extracts tabular features like MFCC, Chroma, Spectral Flux, and more, for traditional models.
- A custom sound class, Love, was created by recording and segmenting 67 minutes of audio into 1,000 samples.
Project Structure
The repository is divided into two main folders:
- Deep Learning
- DL Feature Extraction: Converts audio files into melspectrogram images.
- EDA: Analyzes the extracted features for insights.
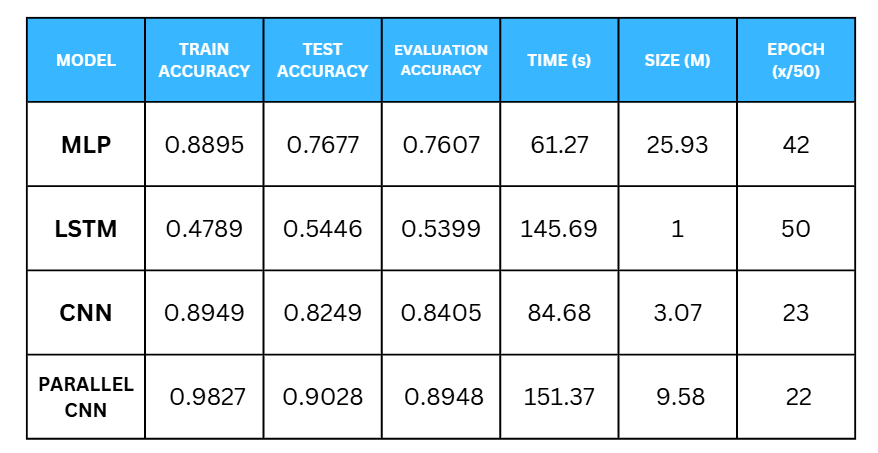
- DL Modeling: Trains various models, including MLP, LSTM, CNN, and Parallel CNN.
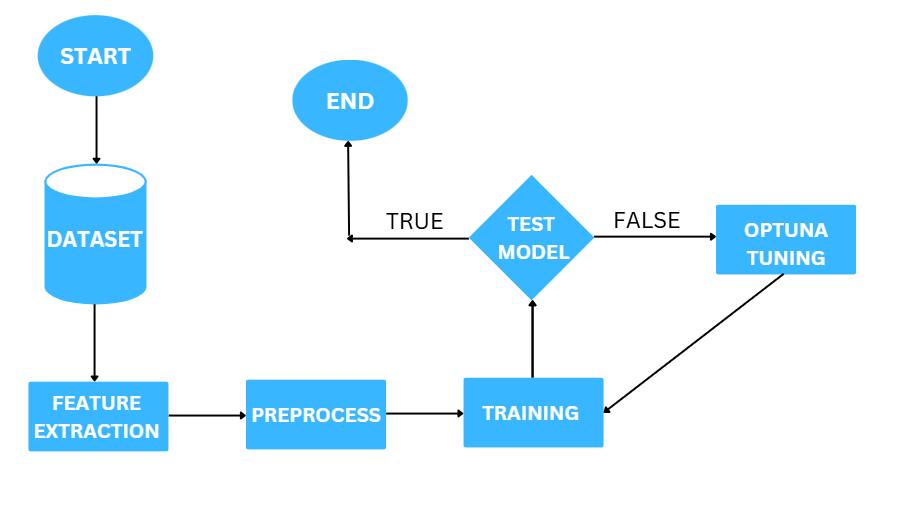
- Hyperparameter Training: Optimizes the CNN model using Optuna, striking a balance between performance and computational cost.
- Machine Learning
- ML Feature Extraction: Extracts audio features for tabular datasets, including MFCC, Chroma, and Spectral Flux.
- ML EDA: Examines the tabular dataset for trends and patterns.
- ML Modeling: Trains models like KNN, CART, Random Forest, XGBoost, and LightGBM.
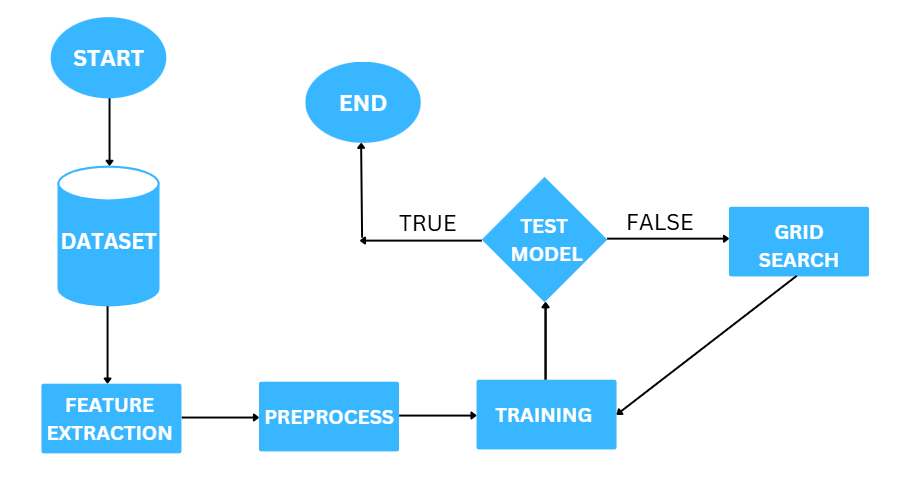
- LGBM parameters are optimized using GridSearch
Deep Learning Pipeline
Machine Learning Pipeline
Key Features
- Custom Sound Class (Love): A new sound category was introduced, featuring audio labeled as “Love” to expand the UrbanSound8K dataset.
- A/B Testing: Detailed statistical analysis was conducted to evaluate:
- The effectiveness of the new “Love” class.
- The impact of different scaling techniques (Min-Max, Standard, Robust) on model performance.
- Feature Engineering:
- Melspectrograms for Deep Learning models.
- Tabular features like MFCCs for Machine Learning models.
- Hyperparameter Optimization:
- Optuna for CNN tuning.
- GridSearchCV for LGBM parameter search.
Statistical Analysis (A/B Testing)
To validate the performance of models and scaling techniques:
- New Class Analysis:
- Models were trained with and without the Love class.
- F1-scores were compared across models using statistical tests, including Shapiro-Wilk, Levene, and Mann-Whitney U, were used to assess differences.
- Scaling Method Analysis:
- Min-Max, Standard, and Robust scalers were applied.
- Statistical tests, Levene and MultiComparison were used to assess differences.
Conclusion
This project highlights an innovative exploration of urban sound classification, combining deep learning and machine learning techniques with rigorous statistical evaluation. By leveraging the UrbanSound8K dataset, optimizing models like CNN, and introducing custom class creation with A/B testing, it bridges theory and practical application.
The work lays a solid foundation for future research, encouraging further advancements in audio analysis and sound classification. Thank you for exploring this journey with us—may it inspire your own discoveries in this exciting field!